Mybatis框架介绍与基本使用笔记
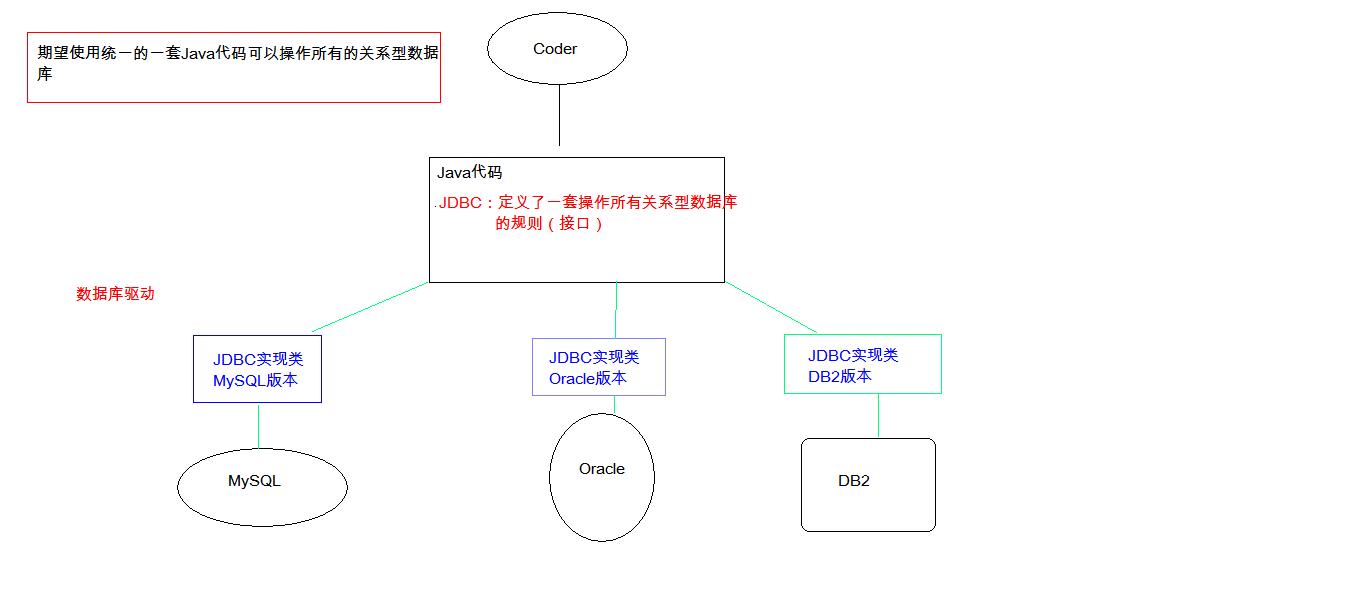
注意:一般的一个Maven工程首先注入的依赖包含数据库驱动依赖,日志依赖,测试依赖
domain中的实体类实现serizlizable接口序列化的原因:
最重要的两个原因是:
1、将对象的状态保存在存储媒体中以便可以在以后重新创建出完全相同的副本;
2、按值将对象从一个应用程序域发送至另一个应用程序域。
实现serializable接口的作用是就是可以把对象存到字节流,然后可以恢复。所以你想如果你的对象没实现序列化怎么才能进行网络传输呢,要网络传输就得转为字节流,所以在分布式应用中,你就得实现序列化,如果你不需要分布式应用,那就没那个必要实现序列.
namespace:名称空间;写接口的全类名;相当于告诉Mybatis这个配置文件是实现哪个接口的;